35 Interesting and Unique Types of Neural Networks
Artificial Neural Networks (ANNs) are a fundamental underlying piece of technology found in a vast range of artificial intelligence models.
Based largely on the biological systems seen in the human brain, neural networks are computational models that consist of interconnected nodes, or artificial neurons, organized into layers. There are many types of neural networks with new approaches being developed frequently.
In this article, I’ve taken a deep dive into 35 different types of neural networks and when to use them. ---
What is a Neural Network?
A neural network, or more precisely an artificial neural network (ANN), is a subset of machine learning that mimics the network of neurons in a brain to process complex data inputs.
These networks can adapt, learn, and improve over time, forming the backbone of what we know as Artificial Intelligence.

Different types of neural networks include recurrent neural networks (RNNs), often used for text and speech recognition, and convolutional neural networks (CNNs), primarily employed in image recognition processes.
To state it simply, neural networks contribute to making decisions and predictions through a process similar to human reasoning.
Learn more about neural networks by reading some of these top machine learning books.
What Are the Different Types of Neural Networks?
1. Feedforward Neural Network (FNN)
Feedforward Neural Networks, one of the simplest types of artificial neural networks, are essential in deep learning and artificial intelligence for their straightforward neural network architecture.
Feedforward networks are considered simple as they do not recycle information as they lack the feedback connections found in recurrent neural networks and convolutional neural networks.
These networks consist of multiple layers, including an input layer to receive input data, hidden layers with artificial neurons and activation functions for processing, and an output layer for the final decision or prediction.
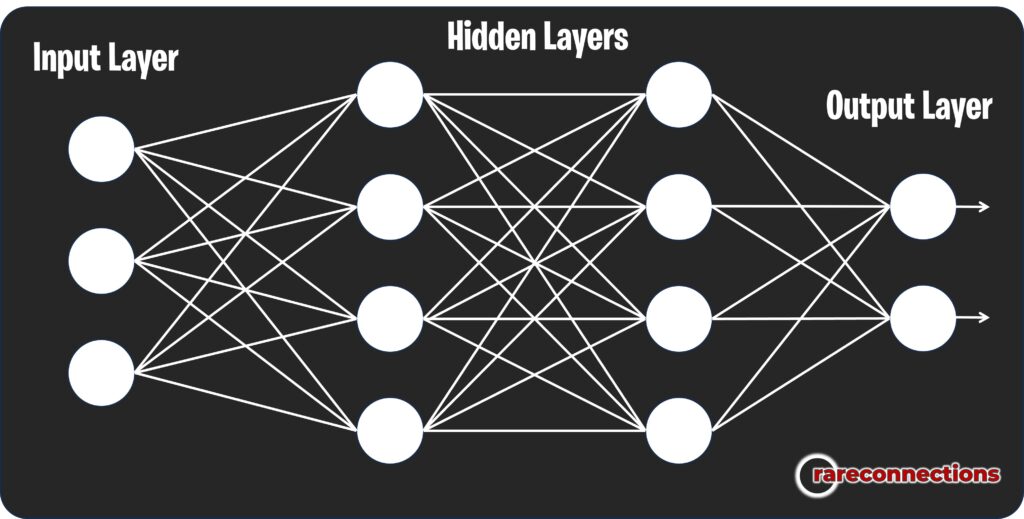
Feedforward neural networks are predominantly used in pattern recognition, image classification, and other machine learning tasks where sequential data processing is not required, relying instead on a direct flow of information from input to output.
2. Multilayer Perceptron
A Multilayer Perceptron (MLP) is a type of feedforward neural network, consisting of at least three layers: an input layer, multiple hidden layers, and an output layer.
Featuring interconnected artificial neurons with nonlinear activation functions, MLPs excel in complex function approximation, pattern recognition, and binary classification tasks, making them foundational in supervised learning tasks.
Unlike recurrent or convolutional neural networks, which are specialized for sequential data or image processing, respectively, multilayer perceptrons are versatile deep neural networks ideal for a broad spectrum of applications from natural language processing to computer vision tasks.
Their ability to learn directly from input data through backpropagation and adapt their internal parameters makes them powerful tools in both traditional machine learning algorithms and more advanced deep learning algorithms.
AI breakfast is one of my favorite AI newsletters and is worth a look for everything technical in AI delivered to your inbox.
3. Radial Basis Function Neural Network
The Radial Basis Function Neural Network (RBFNN) is a unique type of artificial neural network that primarily focuses on function approximation.
It is structured with an input layer, a hidden layer with radial basis functions as activation functions, and an output layer.
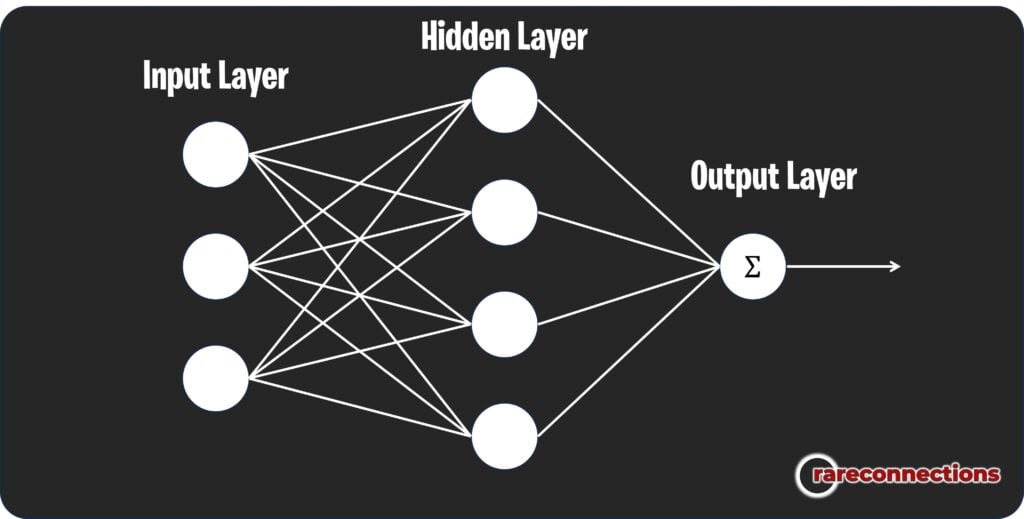
Unlike other neural networks, RBFNNs are particularly adept at solving problems that require the mapping of inputs to outputs through a nonlinear function, making them excellent for pattern recognition and interpolation tasks.
This capability stems from their design to approximate any smooth function.
RBFNNs are highly suitable for applications involving function approximation, pattern recognition in machine learning, and situations where the relationship between input and output data needs to be closely and accurately modeled, leveraging their adaptive system to fine-tune the response to input data.
4. Convolutional Neural Network (CNN)
Convolutional Neural Networks are primarily used for image processing and were originally inspired by the organization of the visual cortex in the human brain.
What sets convolutional neural networks apart is their unique architecture: they use convolutional layers, pooling layers, and fully connected layers, all designed to automatically and adaptively learn spatial hierarchies of features from inputs. In simpler terms, CNNs are like automatic pattern finders.
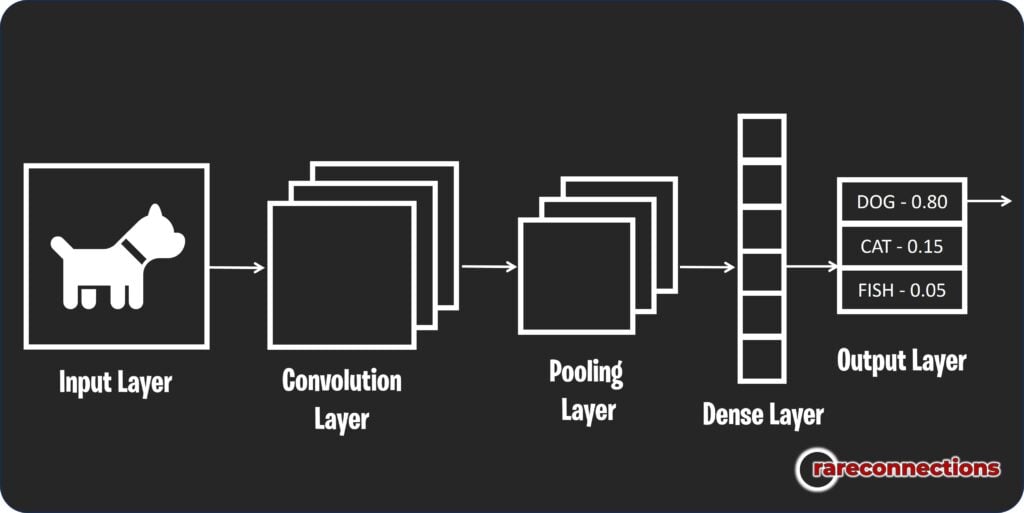
Imagine trying to identify a dog in a picture. A CNN starts by recognizing simple shapes and textures (e.g., lines, curves), then assembles these into more complex patterns (e.g., ears, eyes), and finally combines these into a high-level representation of a dog.
CNNs are particularly good at understanding the spatial structure in data, making them ideal for tasks like facial recognition. Traditional neural networks may struggle to recognize a face turned sideways, but a CNN can learn to understand the ‘face’ pattern regardless of its orientation or position.
5. Recurrent Neural Network (RNN)
A recurrent neural network is a type of neural network designed to recognize patterns in sequences of data, like text, speech, or time-series data.
The standout feature of RNNs is their “memory” – they take information from previous steps into account in their processing, unlike other neural networks that treat each input independently.
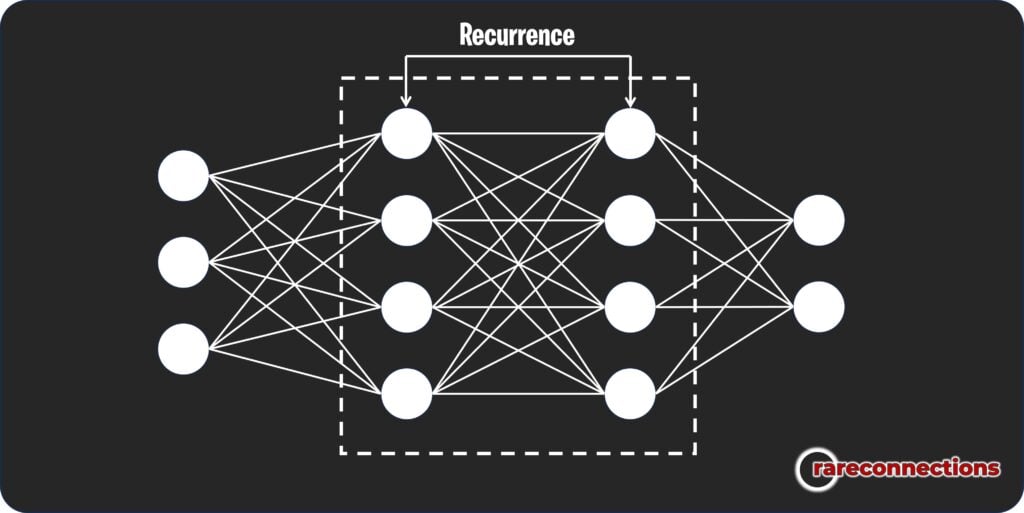
Let’s imagine RNNs as people reading a book: they remember what they’ve read before and use that context to understand what they’re currently reading. This memory makes RNNs great for natural language processing tasks.
The sequential nature of RNNs makes them an ideal choice when the order of data points matters, such as in time series prediction, speech recognition, or any other task that involves sequential data.
6. Long Short-Term Memory (LSTM)
Long short-term memory networks are a type of recurrent neural network that are particularly good at learning from long sequences of data.
What makes LSTMs unique is their ability to remember and use information from many steps back in the sequence, overcoming the “short-term memory” issue of basic RNNs which struggle with long-term dependencies due to the problem known as “vanishing gradients”.
This makes LSTMs perfect for tasks like text generation: for example, if a character was introduced at the start of a book, an LSTM can remember to include references to that character much later.
When dealing with long sequences where context from earlier inputs is crucial, LSTMs are often the best choice.
7. Gated Recurrent Units
Gated Recurrent Units (GRUs) are a type of recurrent neural network (RNN) suited for sequences or time series data, making them highly effective in natural language processing, speech recognition, and other tasks involving sequential data.
Unlike traditional RNNs that suffer from vanishing and exploding gradient problems, GRUs tackle these issues with a specialized neural network architecture featuring gates that control the flow of information.
These gates help in retaining long-term dependencies and discarding irrelevant information, respectively, without the need for multiple hidden layers.
GRUs simplify the model complexity and computational expense found in another advanced RNN variant, the Long Short-Term Memory (LSTM), while delivering comparable performance.
They are particularly favored for applications requiring efficient learning over long sequences with fewer parameters, such as deep learning algorithms in artificial intelligence for tasks where understanding temporal dynamics is crucial.
8. Autoencoders
Autoencoders are a special type of neural network used for learning efficient representations of input data, also known as encoding, and then reconstructing the data from these encodings, known as decoding. The unique feature of autoencoders is their ability to compress data into a lower-dimensional form and then rebuild it.
You can think of autoencoders like an artist trying to simplify a complex landscape into a sketch. The sketch is the compressed version of the scene, capturing its most important features. Later, the artist uses the sketch to recreate the full scene.
One popular use case for autoencoders is in image denoising. If you have a picture with noise (like graininess or random dots), an autoencoder can learn to remove that noise and reconstruct a cleaner version of the image.
Autoencoders are chosen when we need to reduce dimensionality or noise, or when we want to learn more efficient representations of our data.
9. Variational Autoencoder
Variational Autoencoders are a type of autoencoder with a twist. While traditional autoencoders can compress data and then rebuild it, Variational Autoencoders add a probabilistic spin: they make assumptions about the distribution of the input data and use this to generate entirely new data that resemble the originals.
Think of Variational Autoencoders like an architect learning to draw houses by studying a range of house designs. Once the architect has a good understanding of what makes a house, they can then draw new houses that are similar to the ones they studied, but not exactly the same.
A use case for Variational Autoencoders is in generating new content that is similar to a training set. For instance, after learning from thousands of images of faces, a Variational Autoencoder can generate images of new, realistic faces that have never been seen before.
These networks are chosen when we need to not only learn from data but also generate new, similar data, like in content generation or simulation.
10. Generative Adversarial Networks
A Generative Adversarial Network is a type of neural network known for its ability to generate new, synthetic data that resemble real data.
The network consists of two parts: a “generator” that creates new data, and a “discriminator” that tries to distinguish between real and synthetic data. The two parts work in competition, with the generator improving its creations based on feedback from the discriminator.
Imagine a forger trying to create a convincing fake painting, while an art expert tries to spot the forgery. The forger gets better as the expert gets harder to fool, resulting in an ever-improving fake.
One use-case for Generative Adversarial Networks is in creating realistic computer-generated imagery. For example, they can generate realistic images of landscapes, people, or objects that don’t actually exist.
These networks are chosen when we want to create new, realistic data from a learned distribution, such as in art, gaming, or simulation.
11. Self Organizing Maps
Self-organizing maps are a type of artificial deep neural network designed to perform unsupervised learning, reducing the dimensionality of data while preserving topological properties. The unique aspect of self-organizing maps is their ability to create a “map” where similar inputs are clustered together in the same region, revealing hidden patterns or correlations in the data.
Imagine a librarian who has many different types of books and wants to organize them by topic. A self-organizing map would be like a helpful assistant that reads all the books, identifies their subjects, and then places them on the shelves in a way that similar topics are located close to each other.
A use case for self-organizing maps is in customer segmentation for marketing. By inputting customer data, the network can group similar customers together, helping to identify and target distinct customer segments.
We opt for self-organizing maps when we have high-dimensional data and want to understand the underlying structure or patterns.
12. Neural Architecture Search
Neural Architecture Search, also known as NAS, is a method used in machine learning to automate the design of artificial neural networks. The unique aspect of NAS is that it essentially uses machine learning to create machine learning models: given a dataset and a task, NAS algorithms explore possible neural network architectures and select the one that performs the best.
Think of NAS like a master chef trying to create the best possible recipe. The chef experiments with various combinations of ingredients, cooking methods, and timings until they find the perfect recipe.
One application of NAS is in improving the efficiency of neural networks. For example, NAS could be used to design a network for image recognition that uses less computational resources than existing designs, making it useful for deploying on devices with limited processing power.
We opt for NAS when we want to find the most efficient network for a specific task without manually designing and testing countless models.
13. Siamese Networks
Siamese Networks are a unique type of neural network, designed to understand how similar or different two comparable things are. These networks take in two inputs and output a similarity measure. The name ‘Siamese’ comes from the fact that these networks use two identical subnetworks, which share the same parameters, to process the two inputs.
Consider Siamese Networks as trained art critics who can tell how similar two paintings are. If you present two pictures, they would measure how closely related they are based on what they’ve learned about art.
A typical use case is in face verification systems, such as unlocking your phone with your face. The network is trained with pairs of images and learns to tell whether two images are of the same person or not.
Siamese Networks are chosen when we have tasks involving comparison or verification, such as signature verification, image recognition, or anomaly detection.
14. Transformers
Transformers are a type of neural network architecture that were introduced in the paper “Attention is All You Need” by Google researchers in 2017.
The uniqueness of Transformers lies in their attention mechanism that weighs the significance of different input components differently. This means they are excellent at understanding context, as they decide which parts of the input to focus on at each step of the processing.
Imagine a Transformer as a reader who can understand not just individual words but also how those words relate to each other and the overall sentence, making the reading more comprehensive and context-aware.
A well-known use-case for Transformers is in language translation, where understanding context is crucial. For example, Google’s language translation service has greatly benefited from Transformer architectures.
We might opt to use Transformers when dealing with sequential data where context and relationships between elements are important, such as natural language processing tasks or time series analysis.
15. Modular Neural Networks
Modular Neural Networks are a type of deep neural network where several different networks, each with their own specific task, work together to make a decision.
What’s unique about this architecture is its division of labor: instead of having one network learn everything, each module specializes in a different part of the problem, working in parallel to process information.
Consider a Modular Neural Network like a team of detectives, each skilled in a different aspect of crime-solving, such as forensics, psychology, or interrogation. Working together, they can solve a crime more effectively than any one of them could alone.
An example use-case is in complex decision-making systems. For instance, an autonomous car may use one module to identify pedestrians, another to recognize traffic signs, and another to plan the route, with all modules collaborating to drive the car safely.
We opt for Modular Neural Networks when dealing with complex problems that can be broken down into smaller, more manageable tasks.
16. Sequence-to-Sequence Models
Sequence-to-sequence is a type of neural network model that converts an input sequence into an output sequence. It’s unique because it allows for input and output sequences of different lengths, and it’s well suited for tasks where the input and output are both sequences, but they don’t align element by element.
Think of it as a translator who listens to an entire sentence in one language, and then translates it into another language. The length of the sentences can vary between languages, but the overall meaning should be preserved.
A use case for sequence-to-sequence models is in machine translation, like translating English text to French. Here, the English sentence is the input sequence, and the French sentence is the output sequence.
We might opt to use sequence-to-sequence models when we have tasks that involve mapping one sequence to another, such as in language translation, speech recognition, or text generation.
17. Cascade-Correlation Neural Networks
Cascade Correlation Neural Networks are a special kind of neural network that introduces a different approach to network growth.
Unlike traditional neural networks which grow by changing weights, cascade correlation networks grow by adding new hidden layers, or “nodes”, into the network. These nodes are frozen after they are added, which allows the network to learn complex representations without the risk of “forgetting” what it has previously learned.
You can think of this network as a company that starts with a small team of generalists. As the company grows and tasks become more complex, it hires more specialized employees who focus on specific areas. The early employees maintain their knowledge and tasks while new ones add more specialized skills.
A use-case could be in a complex pattern recognition task, where the complexity of patterns may increase over time.
18. Time delay Neural Networks
Time-Delay Neural Networks are specifically designed for dealing with sequential data where time-based patterns or time delays play an important role.
The distinctive characteristic of these networks is their in-built delay line that remembers past information for a certain period, which is essential for recognizing patterns or trends in time series data.
Imagine it as a movie critic who not only judges the current scene of a movie but also considers the past scenes to understand the complete storyline.
One use-case of Time-Delay Neural Networks is in speech recognition systems, where understanding the sequence of sounds is important to identify words and sentences correctly. By considering past sounds, the network can better understand the current sound and make more accurate predictions.
We opt for Time-Delay Neural Networks when dealing with time-series data or sequential data where the previous information is crucial for understanding the current context, such as in speech recognition or music analysis.
19. Deep Belief Networks
Deep Belief Networks are a type of neural network that consist of multiple layers of latent variables or hidden units, with connections between layers but not within layers.
The distinctive feature of these networks is that they can learn to probabilistically reconstruct their inputs and discover intricate structures within data.
Imagine these networks as archaeologists who dig deeper and deeper into layers of soil to understand the history and culture of a civilization.
A use case for Deep Belief Networks is in image recognition tasks, where they can learn to identify complex structures within images. For instance, they can be used to detect faces in a picture by recognizing patterns and structures that make up a face.
We might opt to use Deep Belief Networks when dealing with complex data where hidden structures or patterns need to be identified, such as in image recognition, speech recognition, or natural language processing.
20. Liquid State Machines
Liquid State Machines (LSMs) are a type of neural network that deal with time-dependent or dynamic inputs.
These networks maintain a “liquid state” of activity, where the present state is a function of the current input and the recent history of inputs. This feature enables LSMs to process and make predictions on data where timing between events is crucial.
Think of an LSM as a pond where each input is like a stone thrown into the water. The ripples created by the stone (or the input) interact with the ripples from previous stones, creating a unique pattern of waves on the surface.
A use-case for LSMs is in speech recognition, where the sequence and timing of sounds matter. By remembering the recent history of sounds, the network can better understand and predict what’s being said.
We opt for LSMs when dealing with time-dependent or dynamic data, such as in speech recognition or music analysis.
21. Hopfield Networks
Hopfield Networks are a type of recurrent neural network designed to model associative memory. A unique aspect of these networks is that they are fully connected and have symmetric weights, which means each neuron is connected to every other neuron and the strength of the connections are equal in both directions.
Imagine a Hopfield Network as a small town where everyone knows everyone else, and information flows freely and equally among its residents.
A use-case for Hopfield Networks is in pattern recognition tasks, especially those related to memory recall. If you provide a partial or distorted pattern that the network has seen before, it can ‘remember’ and reconstruct the original pattern.
We might opt to use Hopfield Networks when dealing with problems of pattern recognition and memory recall, where the goal is to retrieve complete information based on partial or noisy inputs.
22. Echo State Networks
Echo State Networks are a type of recurrent neural network that stands out for its “echo state” property, meaning it has a short-term memory.
This is due to its distinctive structure that includes a large, fixed, and randomly generated hidden layer called the reservoir. This reservoir processes inputs and transforms them into a higher dimension, which provides a memory of recent inputs.
Picture an Echo State Network as a canyon. When you shout into it, your words echo off the walls for a short while before fading, giving the canyon a brief memory of your words.
A use-case for Echo State Networks is in time-series prediction tasks, such as predicting the next word in a sentence or the future stock prices based on past trends. It uses its echo state property to consider past information when making predictions.
We might opt for Echo State Networks when dealing with tasks that require an understanding of temporal dynamics or sequences, such as natural language processing or financial forecasting.
23. Bidirectional Recurrent Neural Networks
Bidirectional recurrent neural networks are a type of neural network that are designed to take into account both past and future context. This is accomplished by having two layers of neurons that process the inputs in opposite directions: one layer processes the sequence from start to end, while the other processes it from end to start.
Imagine this network as a reader who reads a sentence both forward and backward to understand the complete context of each word.
A use-case for Bidirectional Recurrent Neural Networks is in language translation, where understanding the full context of a word (both the words that precede and follow it) can help in more accurate translation.
We might opt for Bidirectional Recurrent Neural Networks when dealing with tasks that require understanding of the full context, both past and future, such as in language translation, speech recognition, or any sequential data processing.
24. Restricted Boltzmann Machines
Restricted Boltzmann Machines are a type of artificial neural network known for their two-layer structure and their unique learning abilities.
They consist of visible and hidden units, but connections only exist between these two layers, not within them. This restriction allows them to learn a probability distribution over the inputs, making them capable of generating new samples that are similar to the inputs.
You can think of these networks as party planners who observe the guest list (inputs) and the interactions among guests to better plan future parties (generate new samples).
A use-case for Restricted Boltzmann Machines is in recommendation systems. For instance, they can learn the viewing patterns of users on a movie platform and then generate recommendations for movies that a user is likely to enjoy.
We might opt to use Restricted Boltzmann Machines when we need to discover hidden features in the data or generate new samples, such as in recommendation systems or generative models.
25. Extreme Learning Machines
Extreme Learning Machines (ELMs) are a type of neural network unique for their speed and simplicity. They have a single layer of hidden nodes, and only the weights connecting these nodes to outputs are adjusted during training, while the others are randomly assigned and left untouched. This makes them exceptionally quick to train.
Think of ELMs as a quick thinker, rapidly making decisions.
A use-case is in large-scale image classification tasks, where quick processing is key. Given numerous images, an ELM can swiftly classify each image into categories.
We might opt for ELMs when dealing with large datasets where computational efficiency is crucial, and we can tolerate a trade-off in precision for speed.
26. Neural Turing Machines
Neural Turing Machines combine neural networks with external memory resources, like a human using a piece of paper while doing complex calculations. This allows them to store and retrieve data over time, making them excellent at handling tasks with long-term dependencies.
Imagine these as accountants, storing transactions and recalling them when needed.
A use-case is in algorithm learning, where they can learn to reproduce sequences or sort lists.
We might opt for Neural Turing Machines when we need a network capable of handling complex tasks with long-term data dependencies, like learning and executing algorithms.
27. Capsule Networks
Capsule Networks are unique as they encode spatial hierarchies between features, which allows them to maintain detailed information about the object’s pose and composition. This helps them to better understand and preserve the intricate spatial relationships in an image.
Imagine these networks as architects who understand how different parts fit together to form a structure.
A use-case is in object recognition tasks, where understanding the relationship between object parts is crucial.
We might opt for Capsule Networks when dealing with tasks requiring a deeper understanding of spatial hierarchies and relationships, such as in advanced image recognition tasks.
28. Spike Neural Networks
Spike Neural Networks (SNNs) are unique as they communicate through spikes, or brief bursts of electrical activity, mimicking how neurons in the brain communicate. This makes them highly efficient, as they only activate when needed.
Imagine SNNs as messengers who only relay important messages, conserving energy.
A use-case for SNNs is in real-time event detection systems, where they can quickly react to important changes in the input data.
We might opt for SNNs when dealing with tasks that need efficient, real-time processing, especially when power usage is a significant concern, such as in embedded systems or battery-powered devices.
29. Probabilistic Neural Networks
Probabilistic Neural Networks are unique for their approach to decision-making. Instead of finding the hyperplane that best separates classes like many networks, they estimate the probability of a new input belonging to each class based on the distance to training examples.
Think of them as detectives who, instead of focusing on a single clue, consider the likelihood of each suspect being guilty.
A use-case is in medical diagnosis, where they can predict the likelihood of a patient having a certain disease based on symptoms.
We might opt for Probabilistic Neural Networks when handling tasks that require probabilistic decisions, such as diagnosis or risk assessment.
30. Neuro-Fuzzy Networks
Neuro-fuzzy networks combine the interpretability of fuzzy systems with the learning capability of neural networks. This allows them to handle uncertainties in data and still learn from it, providing clear reasoning for their decisions.
Think of these networks as skilled translators, converting human-like reasoning (fuzzy logic) into numerical data (neural networks) and vice versa.
A use-case is in weather forecasting, where they can handle uncertainties in data and still provide accurate predictions.
We might opt for neuro-fuzzy networks when dealing with complex tasks involving imprecise or noisy data, where a balance of interpretability and learning capability is crucial.
31. Deep Residual Networks
Deep Residual Networks are unique for their ability to train extremely deep neural networks without difficulty. They achieve this through skip connections, or shortcuts, which allow the gradient to be directly back-propagated to earlier layers.
Imagine these networks as hikers who build bridges across tough terrains, making the path easier.
A use-case is in image recognition tasks, where they have achieved top results by exploiting very deep architectures.
We might opt for Deep Residual Networks when dealing with tasks that require deep networks, such as advanced image or speech recognition tasks, where they can learn complex patterns from data.
32. Dense Networks (DenseNet)
Dense Networks, often referred to as fully connected networks, are unique because every neuron in one layer is connected to every neuron in the next layer. This design ensures that the network learns a comprehensive representation of the input data.
Imagine these networks as detectives who examine every possible clue to solve a mystery.
A use-case is in classification tasks, where dense networks can be employed to learn complex representations from a vast array of features.
We might opt for Dense Networks in scenarios where the relationships between all features need to be considered, like in complex classification or regression tasks.
33. Dilated Convolutional Networks
Dilated Convolutional Networks is a type of convolutional neural network and are unique for their expanded receptive field, achieved by introducing gaps into the kernel of the convolutional layers. This enables the network to incorporate a larger context without increasing the computational cost or losing resolution.
Imagine these networks as people using binoculars with a wider field of view to spot objects far away.
A use-case is in semantic image segmentation, where understanding a larger context is crucial for assigning labels to every pixel.
We might opt for Dilated Convolutional Networks when dealing with tasks where a broader understanding of context is beneficial, such as in image or sound segmentation tasks.
34. Deformable Convolutional Networks
Deformable Convolutional Networks are unique because they allow the convolutional filters to adapt their shape to the input data, rather than being rigidly defined. This flexibility makes them particularly good at handling distortions and variations in the input.
Imagine these networks as flexible gloves that adapt to the shape and size of the hand they’re worn on.
A use-case is in object detection tasks, where objects can appear in various shapes and orientations.
We might opt for Deformable Convolutional Networks when dealing with tasks involving distorted, varied or complex patterns, where a degree of adaptability and flexibility in feature extraction is essential.
35. Graph Neural Networks
Graph Neural Networks are unique as they specialize in processing data structured as graphs. They capture relationships between data points, which is not possible with traditional neural networks.
Think of these networks as social scientists analyzing connections within a social network.
A use case is in social network analysis, where they can infer information about individuals based on their relationships.
We might opt for Graph Neural Networks when dealing with data represented as graphs, like social networks, molecular structures, or web pages, where the relationships between data points are as important as the data points themselves.
Final Thoughts
Exploring the expansive landscape of neural network types, from traditional feedforward networks to complex recurrent and convolutional architectures, underscores the massively diverse capabilities and applications of artificial neural networks in today’s world.
These neural network architectures, inspired by the human brain’s interconnected neurons, have propelled advancements in deep learning, computer vision, natural language processing, and beyond.
The intricate design of these networks, featuring multiple layers, activation functions, and unique data processing methods, allows them to excel in tasks ranging from image classification to speech recognition, outperforming traditional machine learning algorithms in many areas.
As people continue working in AI and our understanding deepens, the potential of neural networks in simulating human intelligence and solving complex, real-world problems becomes increasingly boundless, highlighting their pivotal role in the ongoing evolution of artificial intelligence.